
谷歌新发布的 Gemini Omni 模型,这两天可谓是口碑两极分化。


Gemini Omni首发能力就是视频生成。它也被称为“全模态”模型,因为:
任意输入:它可以接收文字、图片、音频、视频等多种形式的指令。
强大输出:它能根据这些指令生成完整的视频,并支持“对话式编辑”,你可以用聊天的方式让它修改视频。
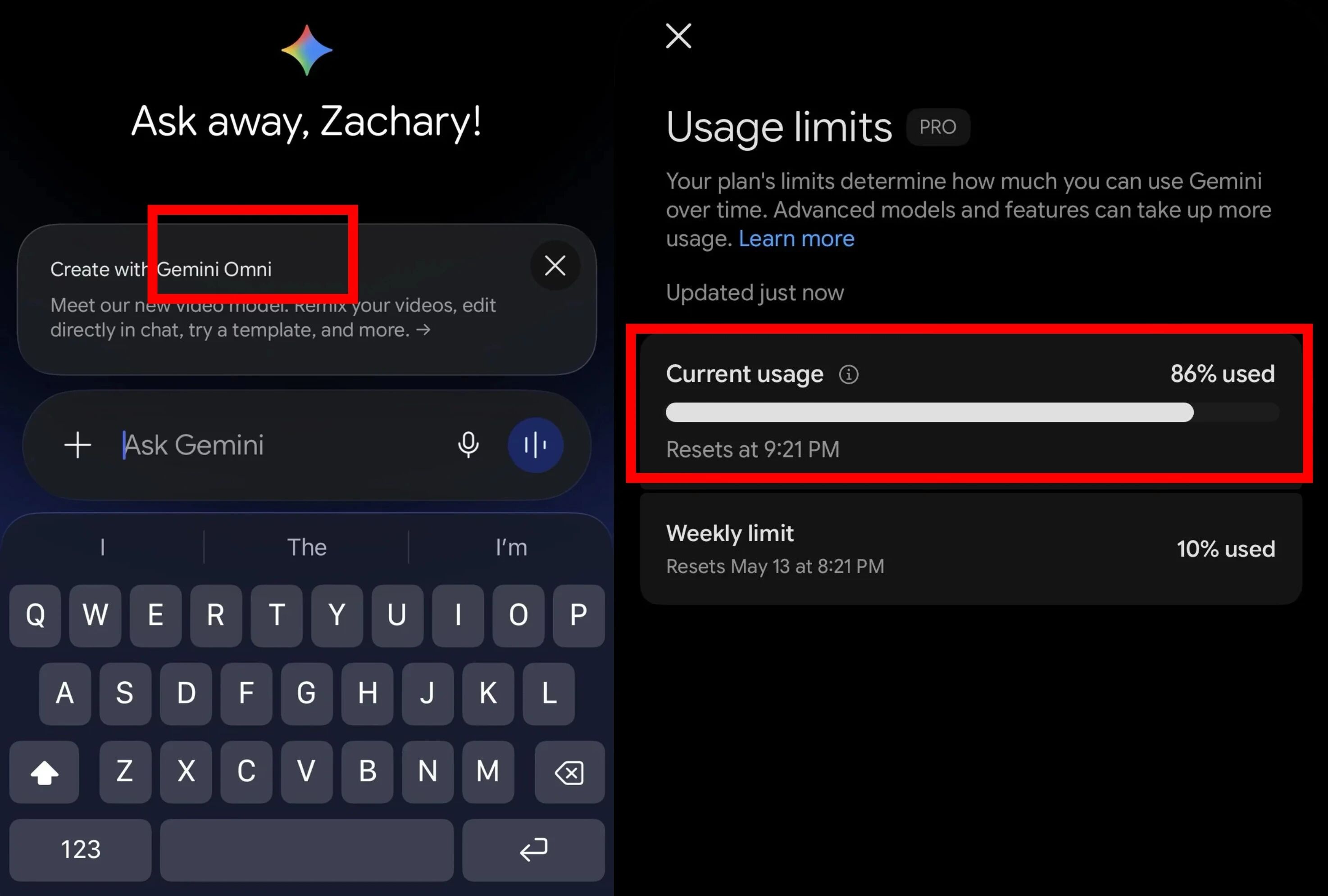
在Gemeni Omni 上线一周前,一名叫Zachary的用户,就提前收到过Gemeni Omni 的使用邀请。
为此他体验了一下,首先想到测试这款模型性能时,他借用威尔·史密斯吃意大利面的经典画面来考验这款新工具。
但是由于肖像权保护,他只能在提示词做了一些调整,生成两个男人在海边吃意面的画面。
整体还算自然,但穿帮镜头不少:比如两人从见面到落座时,桌上根本没有意面,一坐下就凭空冒出两盘开始吃;另外意面的长度也不对,还没送到嘴边就突然消失了。
接着他又生成了一个视频,演示“一位教授在传统黑板上写出三角恒等式的数学证明,并解释他当前所处的证明步骤”这样的输入。
我们看到,虽然粉笔划过黑板时文字闪现过程还存在一些明显的AI痕迹,但文字和数学公式都正常显示,呈现出相当逼真的效果。
这样的水平放到市场来看,只能说是无功无过吧,不够惊艳却也够用的程度。
然后就来到了谷歌发布会当天,很多人亲自去试了下,发现效果却是不尽如人意。
Omni目前支持最高10秒视频生成,以打斗片段来测试时,效果如下:

同样的提示词,seedance2.0的表现如下:

虽然都说不上完美,但生成效果还是能够一眼高下立判的。
然而,也有声音指出,拿 Omni 和 Seedance 放在一起比较,就像问苹果和梨哪个更好吃——完全是鸡同鸭讲。
更何况,目前 Omni 还只是 Flash 版本,用 3-5 分钟生成一段 10 秒视频的速度,跟 Seedance 2.0 的生成时长根本不在一个量级上。
这俩压根不是同一个赛道的东西,目标场景也完全不同。
Omni 就像它的名字那样,主打轻量、高效,尤其在视频到视频(Video-to-Video) 这个方向表现其实值得期待。
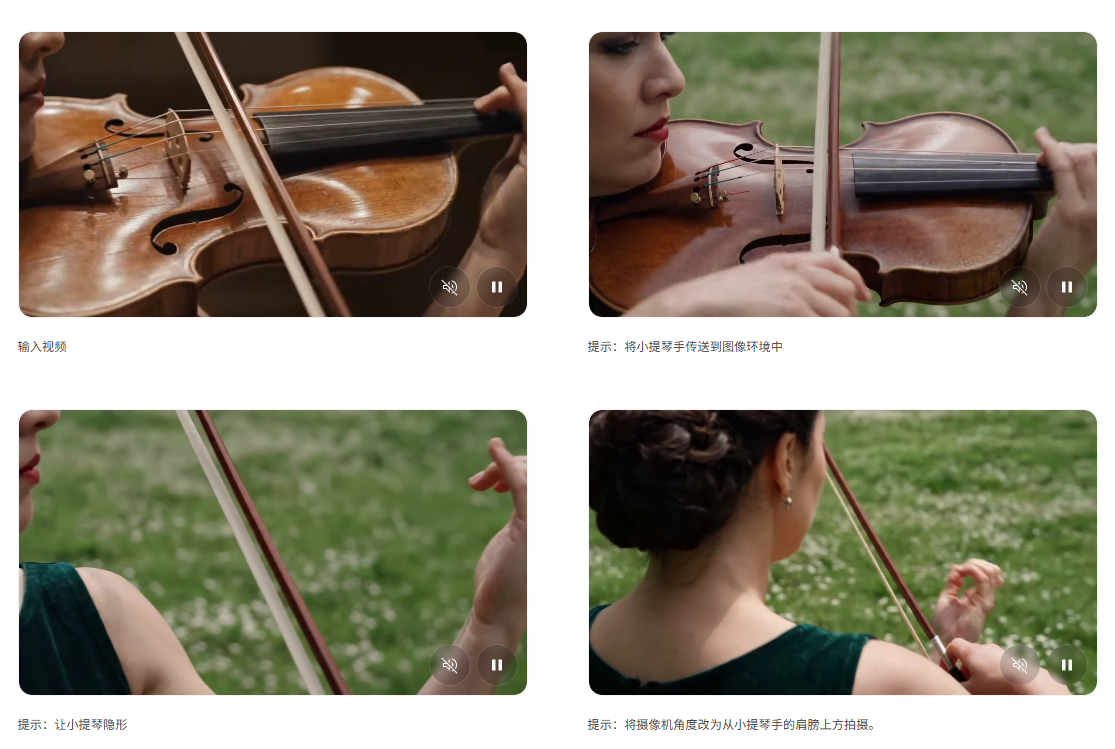
谷歌重点介绍的案例也更多聚焦在视频编辑层面,用户可以编辑自己拍摄的视频或 AI 生成的视频,并调整片段的特定方面。
如果用户喜欢某个镜头但想更换背景,也可以使用 Omni 来实现。Omni 可以调整视频的风格、角度、场景,甚至是片段中的特定细节。
这些都是视频剪辑过程中非常普遍的调整需求,比起一次性生成不可修改,再反复抽卡重新生成这样令人头大的操作,这种精准定位、随处微调可能更实用。
比如下面这段视频,一个用户拍了自家庭院,然后直接语音告诉Omni 让它变更季节和时间,Omni 的操作相当丝滑,而且原视频里的物品几乎保持了原样不动。

再看官方展示的一个案例。AI根据一张静态图片和一段视频,将它们天衣无缝地融合成一个崭新的视频。

抛开对视觉识别和空间逻辑的探讨,Omni 展现的是一种基于现有素材的强加工能力。
而且在前面提到的数学课堂视频案例,教授在传统的黑板上写出三角恒等式的数学证明,并讲解证明步骤。
虽然最终输出结果中仍然存在一些明显的AI痕迹,但在文本生成和动作控制方面表现也还可以。
很多人都有这样体验,以前很多AI生成的内容是经不起细看的,大多数文字在背景里乍一看没问题,但是一放大才发现根本不是文字,而是一堆说不上符号还是乱码的东西。
这意味着AI已经能够克服“图像/视频中文字乱码”这个困扰行业多年的顽固技术难点。这在广告、电影字幕、产品包装设计等专业领域,是一个实用化里程碑。
所以,当大家还在忙着生成各种打斗场面来直接对标时,其实讨论的焦点已经跑偏了,甚至可能会对这款产品形成一种低估甚至误读。
与其说 Omni 是传统意义上的生成模型,不如说它更像是视频版Nano Banana。
最开始Gemini 2.0 Flash 生成原生图像生成效果也谈不上惊艳,但所有人都能看见潜力,六个月之后,Nano Banana 横空出世了。
目前,借助 Gemini Omni Flash,用户还可以通过虚拟形象创建自己的虚拟数字人。不过,谷歌表示仍在测试这项功能,以确保其安全发布。
Gemini Omni Flash当前只面向Gemini 应用和 Google Flow 的付费订阅用户,后续将接入YouTube Shorts 和 YouTube Create 应用,提供免费使用。

PS:欢迎扫描下方海报二维码,预约《2026年上半年AI短剧行业报告》。

| 往期好文推荐
12个平台激战漫剧赛道:分成高达90%,AI内容进入亿级流量
两个月上线三部AI精品漫剧,单剧4天播放破千万,行业进入分水岭?
中文在线首部AI 3D漫剧播放量破5000万,这个新的细分赛道要火了?
上市公司财报里的AI短剧真相:3个月烧掉4亿,由译制剧向本土剧迁移......