
从这个角度来说,镜头控制是进一步降本增效的路径,其代表的内容质量也影响着用户的买单意愿,供需两端都倒逼着AI工具转移竞争核心。
可以看到,部分AI工具的功能迭代方向转为强调可控制、可编辑。比如LibTV近日就推出了新功能“导演台(Director Stage)”,主打让用户用“摆积木”的方式搭建故事空间,也是这么个逻辑。
(截图自LibTV官网:https://www.liblib.tv/)
那么,这个思路在实际创作过程中是不是真的有效?对于行业来说又意味着什么?

当AI导演也能“指挥”演员和机位
做AI短剧,抽卡无法避免。所以,降本的逻辑就是用更少次数抽出更多能用的分镜。
道理都懂,但实际情况是,为了一张构图能用的镜头,常常需要花费大量的时间精力抽卡,创作者和AI之间存在巨大的沟通损耗。
就算把所有细节都写进提示词,AI生成出来的东西还是有偏差的概率,而如果不懂提示词,那抽卡的时间和成本有可能还要再往上涨。以致于部分导演认为,AI不如人“听话”。
在传统影视剧组,真人实拍短剧的导演可以靠自然语言沟通、亲身示范等方式,让镜头和演员都按照自己的想法呈现。
但对于AI导演来说,“指挥”反倒成了卡点——空间关系、人物站位、镜头角度等视觉信息,靠文字天然描述不清。
因为人对于视觉画面的构思、所见都是3D立体的,而单纯执行文字命令的AI很难理解,更别说生成出来。于是,创作者不得不反复修改提示词、加限定词,一遍遍尝试生成。
目前,业内常见的解决方案就是给AI找参考,生成或者找到符合预期的网图。
但生成参考图依旧需要和AI沟通,本质上难点没有变化;在网上找参考图则需要时间,也很难找到百分百符合设想的图片。
另一种思路是像LibTV的“导演台”功能那样,在平台预设的3D环境里直接构建参考,从“用文字猜测画面”到“先摆出来”,让AI照着生成,减少AI理解的偏差。
官方信息显示,导演台是LibTV画布中的轻量级3D构图节点,支持通过多视角截图,快速生成可被AI图像/视频模型理解的构图参考。
我们上手体验了一下,确实是一个非常轻量的功能,能感受到它并不是只给Blender用户准备的,即便没有3D技能基础,也可以流畅使用。
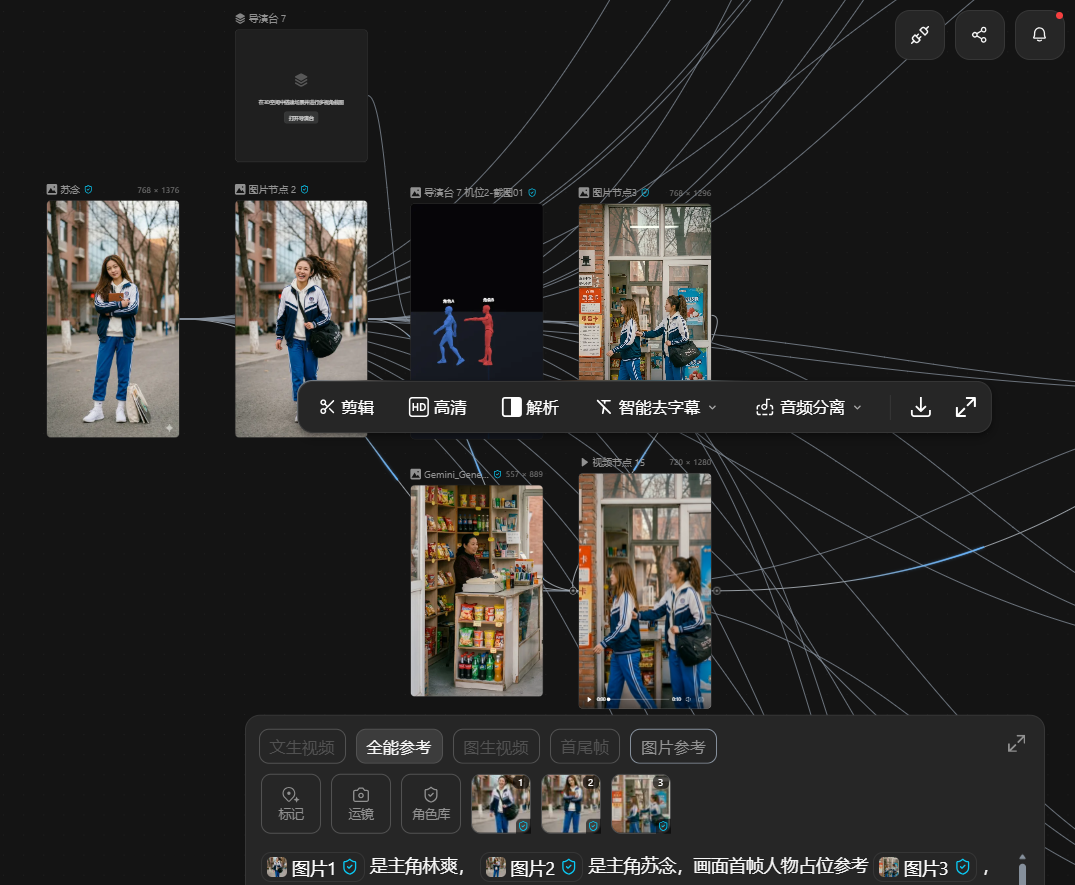
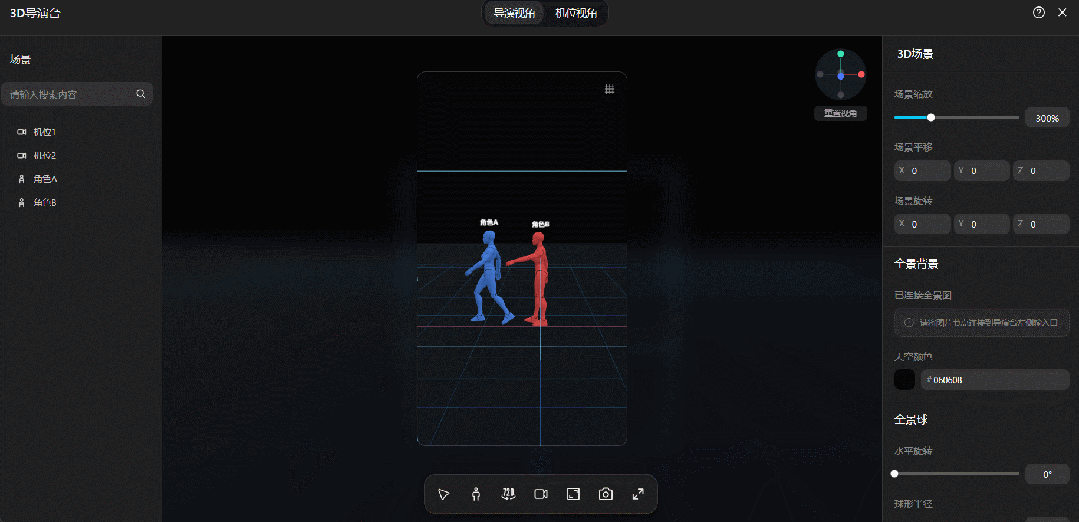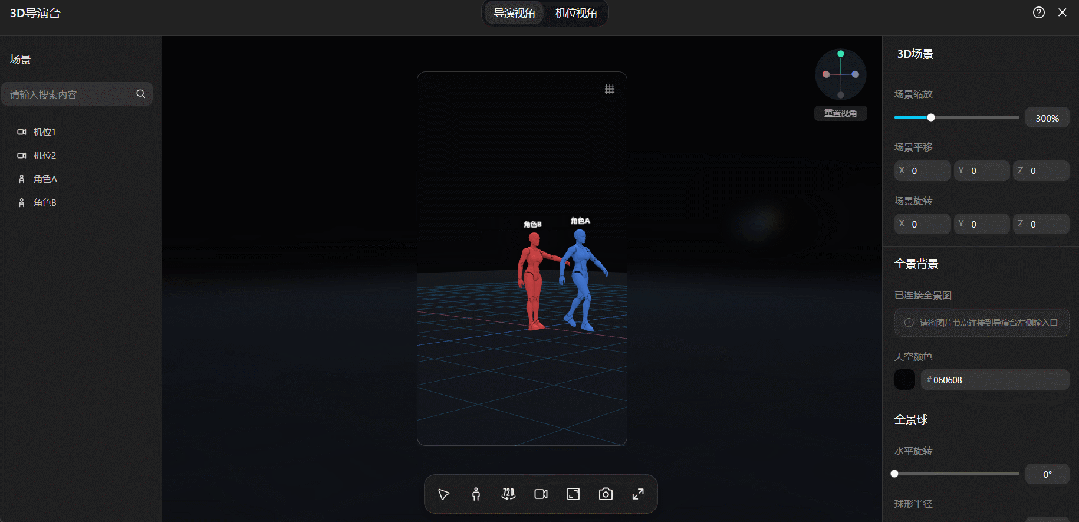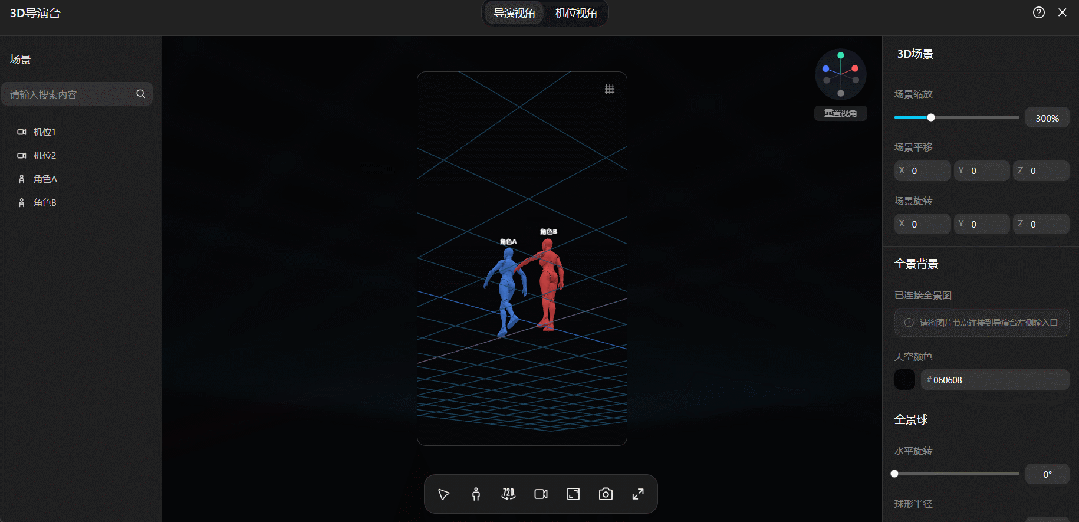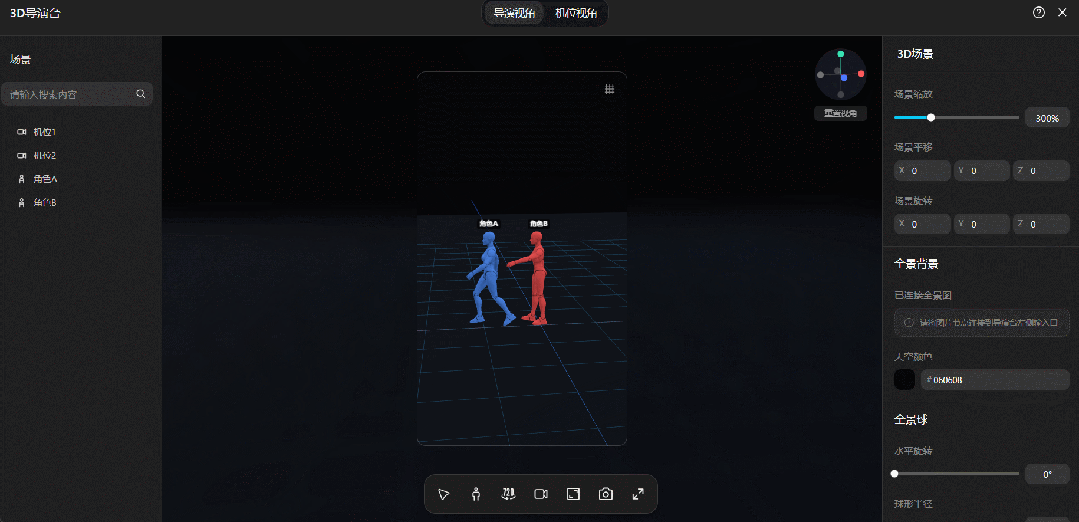
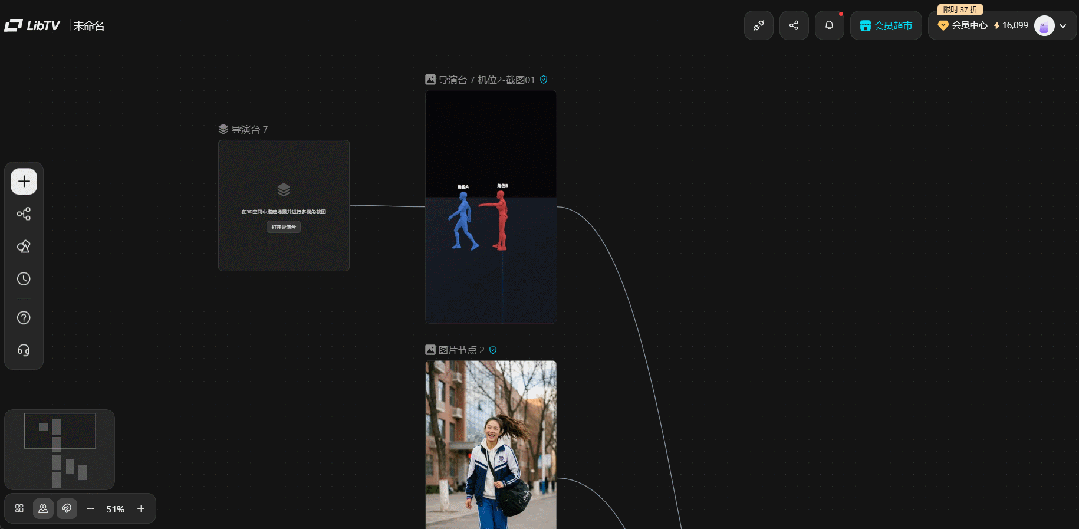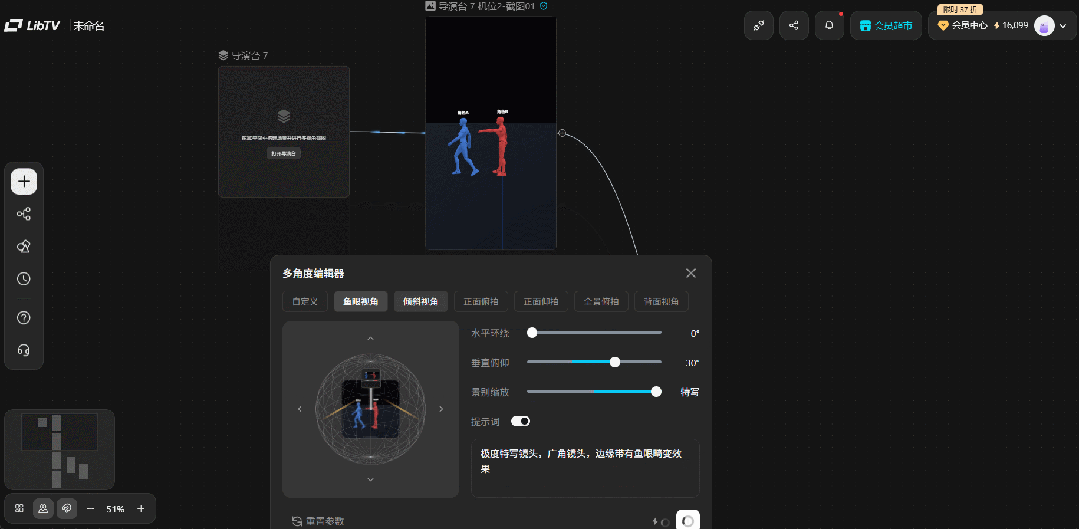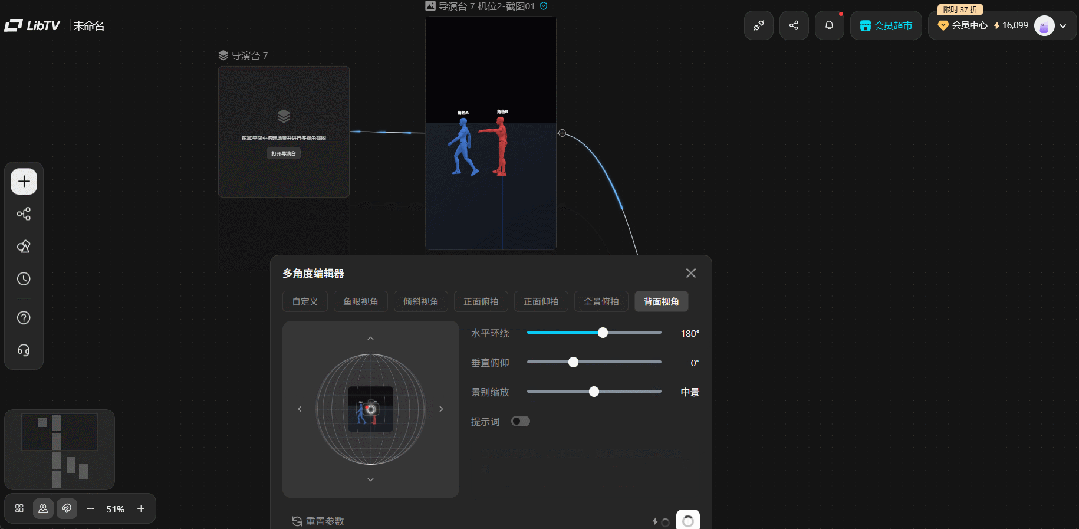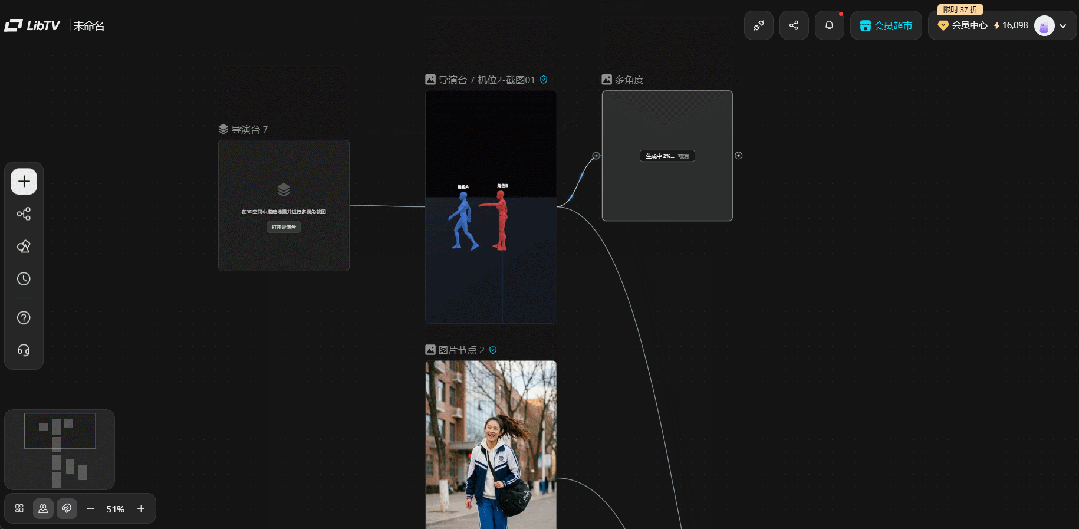
操作界面划分为三个功能区:左边可以选中画布上的模型和机位;中间是视觉效果展示和操作的区域,支持自由摆放模型、增加机位等;右边可以对模型的姿势、场景的缩放等具体属性做进一步调整。
导演台的低门槛源于不需要离开平台、不需要建模,全程只用上了鼠标,点击下方按钮或本地上传,就能生成人体素模、基础几何模型、群众阵列等。
也就是说,只要脑子里有画面,就能在导演台里把它“摆出来”,演员、道具的空间位置一目了然,甚至比“吃鸡”游戏的自由视角都好操作。
(相关动图)
有了可控的素模姿势参考图,加上提前生成的人物、场景素材,AI的“理解能力”可以说是突飞猛进。
比如剧本中两位主角在小卖部门口的站位,我们用上了右侧的“姿势控制”面板:左边女生直接用了系统预置的“行走”姿势,手脚的动作幅度都很自然;右边女生则在默认参数基础上,躯干前倾拉到11,左手臂前举100,右腿前抬12。
从生成结果来看,除了右边女生举起的手有偏差,整体和3D参考的姿势几乎一模一样:
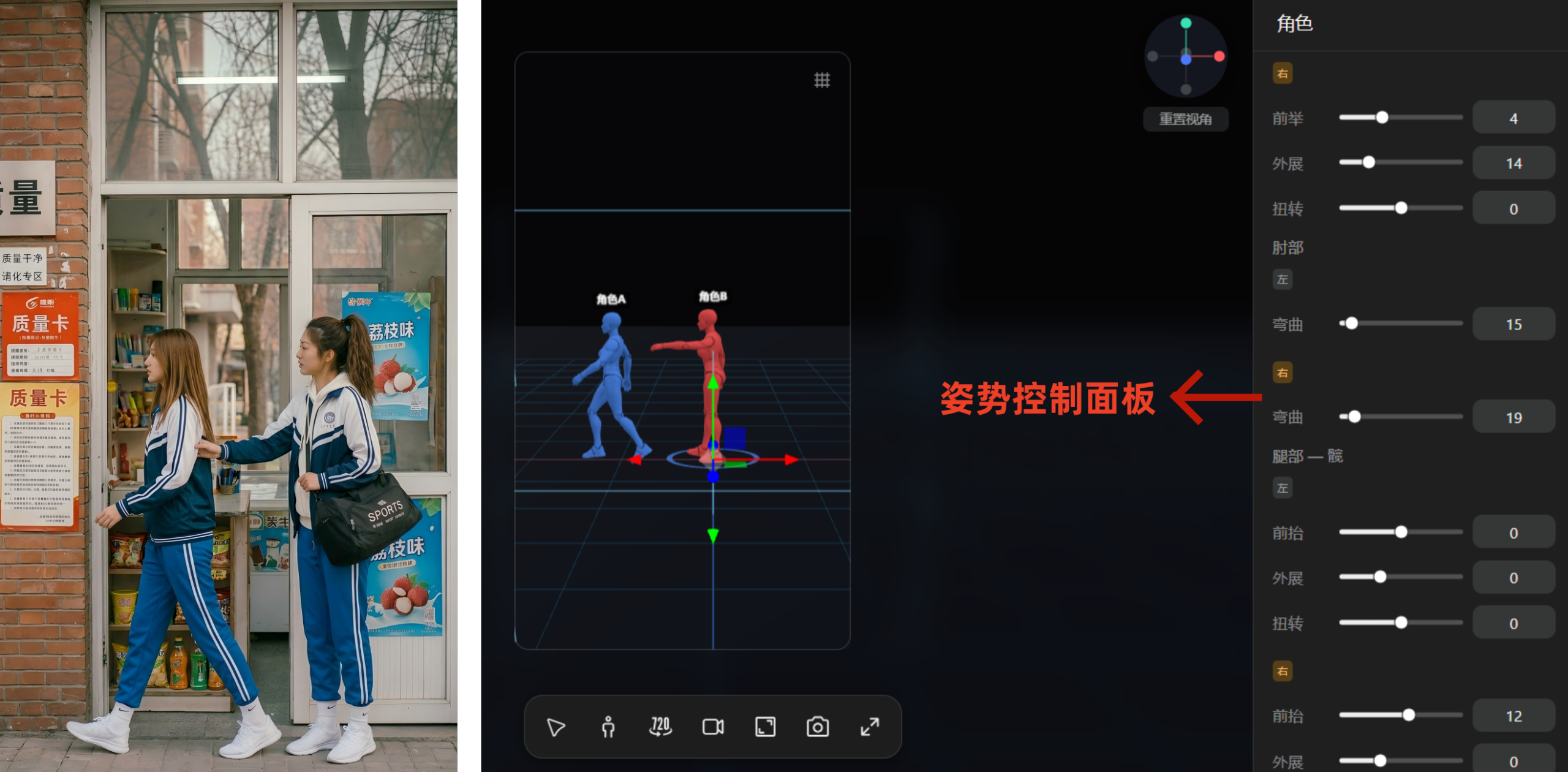
(相关截图)
随着场景变换,参考导演台重新“摆好”的素模站位,两位主角在小卖部冰柜前面的构图依然符合预设,甚至AI还让右边女生的站姿变得更自然:

(相关截图)
这意味着,多人站位控制的精度可以再拔高了。
过去,要出一个两人对话的镜头,得写半天提示词,最后AI生成的画面却是俩人肩并肩站着,谁也不看谁,更别提对戏,和预期差了十万八千里。
如果用上导演台功能,通过移动、旋转、缩放等操作,创作者可以提前设定机位,控制角色姿势,调整人物动作,给AI生成分镜提供一个“构图草稿”,让AI理解谁在前、谁在后、面朝哪、距离多远,有助于提升抽卡成功率。
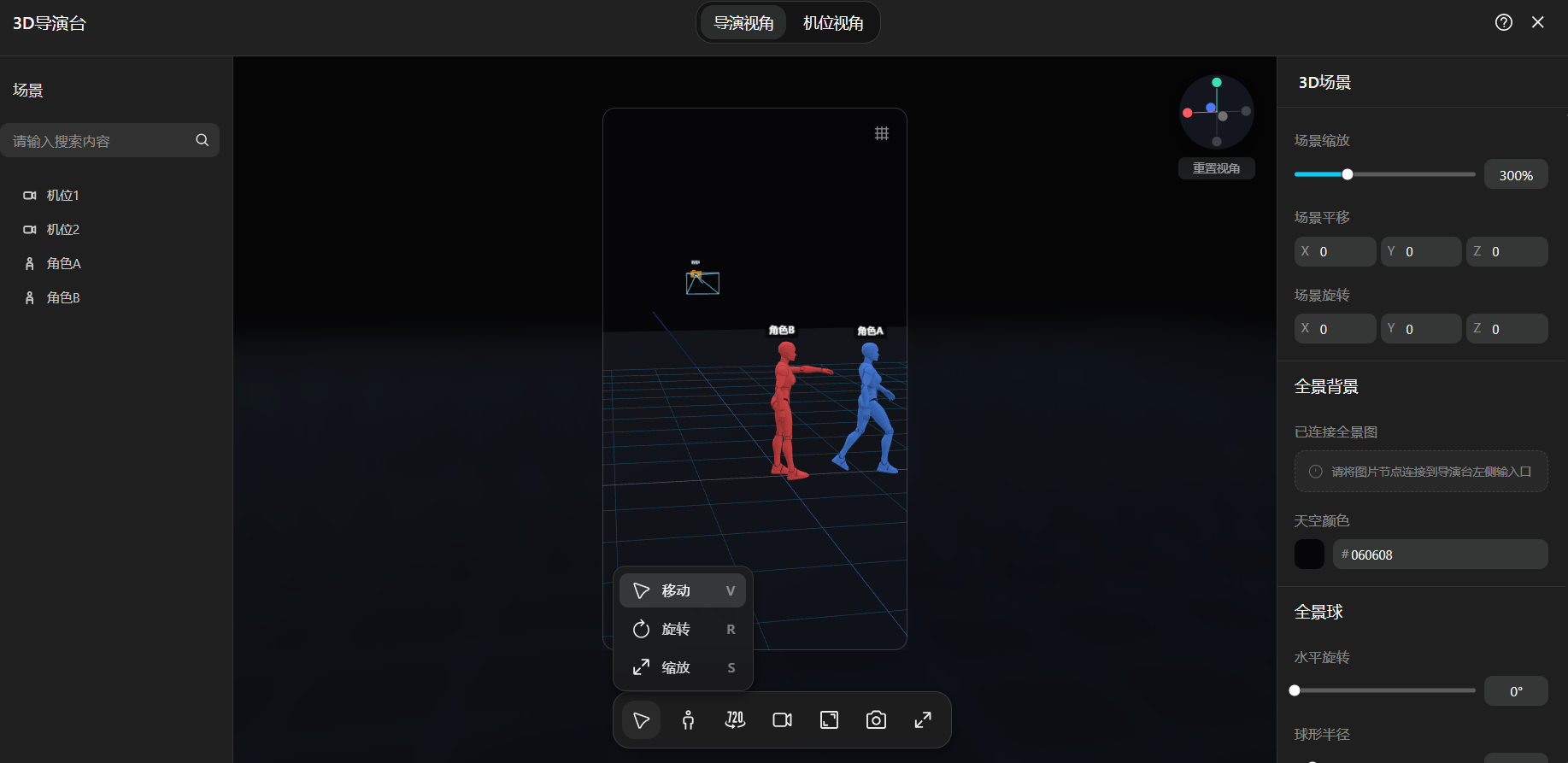
(相关截图)
同时,导演台支持多机位、不同比例截图。创作者只需要在导演台里摆一次素模,可以通过切换机位进行正/侧面、俯视、近景等多角度截图,也可以通过点击“原截图-多角度”的路径,直接生成一套分镜的多视角参考图。
不妨放到创作过程中去理解这个思路:像是车旁对峙、会议室对话、多人围观等镜头,由于涉及到演员站位、机位安排、空间关系,有时候很难靠提示词描述清楚,AI的理解也不一定到位。
在导演台里生成素模和机位截图,相当于真人实拍短剧导演讲戏,演员和剧组工作人员都能够理解导演想要拍出什么感觉,AI也能依据参考生成创作者想要的镜头,减少抽卡的“冤枉钱”。
在这个基础上,多机位截图还能进一步降本——真人实拍时多个摄影机位的人力成本,AI生成多视角分镜的抽卡成本,全网找多视角参考图的时间成本,都能得到不同程度的下降。
(相关动图)
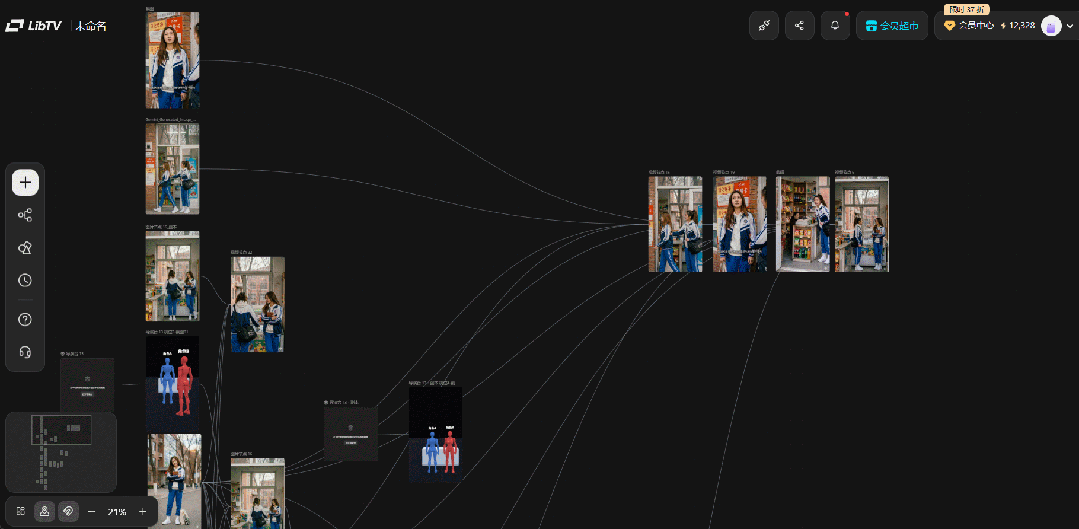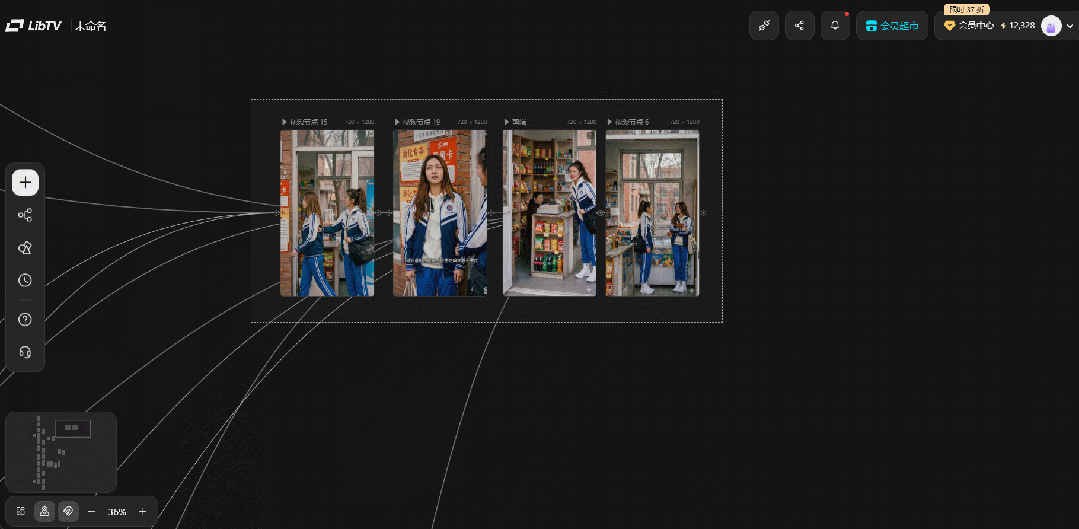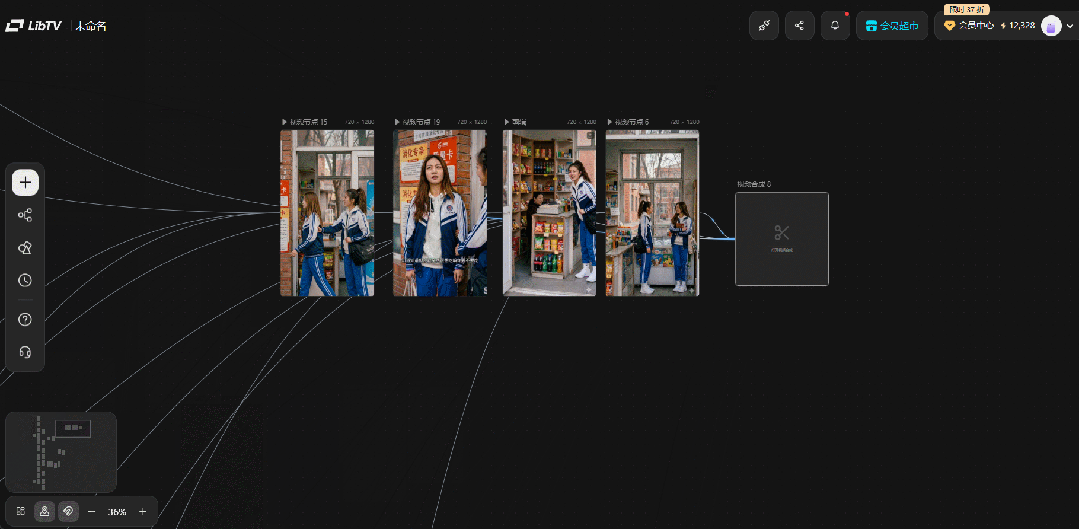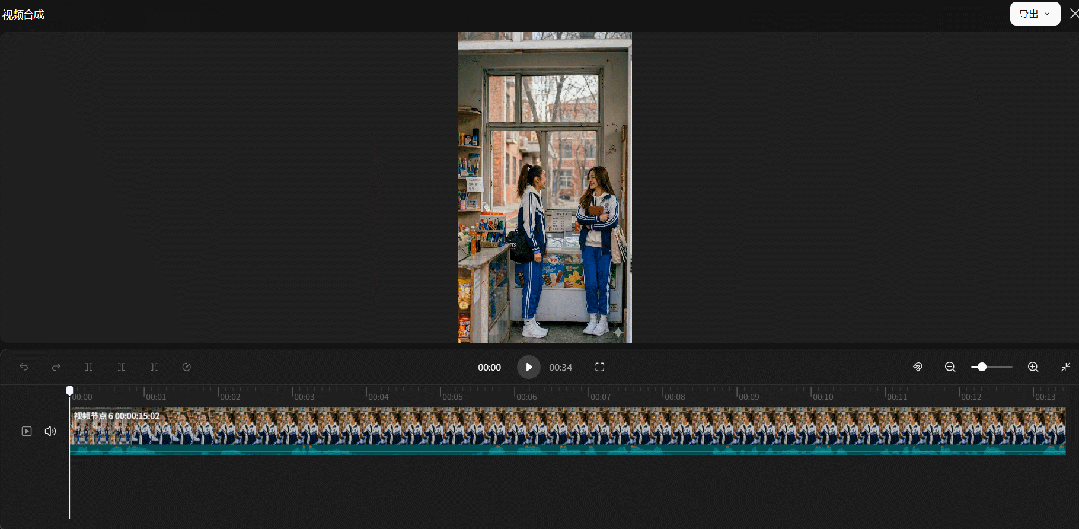
使用导演台功能生成我们想要的构图和视频之后,在LibTV的画布上可以直接完成视频的整合。
(相关动图)
从成片看,导演台的素模构图基本都被很好地执行,整体和预期画面几乎没有偏差,人物、场景、色调风格都保持着不错的一致性。
从工作流看,摆放素模的步骤替代了过去全网找参考的大海捞针,减少了时间精力的花费,反而能够聚焦对画面呈现的思考,AI的参考表现也相对更精准。
隐隐感受到,这说不定会是下一轮AIGC创作热潮的变量。

当AI学会看构图,竞争维度就拓展了
AI短剧要进一步发展,乃至走向主流,需要更多的确定性。
图文生视频的过程相对抽象,需要AI自己根据训练数据来猜测创作者的意图,并补齐大量内容,这种信息传输方式很容易失真,极大影响生成的确定性。
同时,成本的确定性也会因此大打折扣——寻找或者生成参考图都需要花费大量时间,结果不一定百分百符合设想;单次生成的成本叠加不可控的抽卡概率,项目的投入产出比会消减。
这也导致行业的竞争一度变得微妙:谁能把画面翻译成AI更容易理解的语言,谁就更容易出片,部分审美好但不擅长“跟AI沟通”的创作者处于劣势。多少有些倒反天罡了,工具没有适应人,反而是人在适应工具。
从这个角度来看平台内置轻量3D构图功能,相当于在创作者和模型之间加了一个能够低门槛执行的“空间可视化层”。AI不再只靠猜文字来还原画面,而是有了明确的模版,从流程上强化AI视频工具理解三维空间关系的能力。
创作逻辑也因此发生扭转:过去依赖提示词博弈的“抽卡逻辑”,被替换为“先设计,后执行”的专业创作逻辑,即先增加一个用素模验证构图的较低成本确认步骤,再进入资产生成环节,有望成为AI视频工业化生产工作流的重要节点。
更深层的变化,在于创作权力的重新分配。
当3D构图成为创作者与AI之间的“通用语言”后,创作者不再需要成为“提示词工程师”,而只需要知道一个画面应该是什么样的:人物怎么站、镜头从哪拍、空间关系如何。
随着工具适配人的思维,导演、摄影师、美术指导们的核心竞争力,如空间感、构图审美、调度能力等或将重新定价,这必然对行业人才结构产生影响。
这也是LibTV推出导演台新功能引发关注的重要原因。
它将AI视频创作中的构图控制权重新交还给创作者,让创作者的审美经验、调度能力能够低损耗地传递给AI,这是对“人”的价值的确认和放大。
同时,导演台输出的截图,可直接接入LibTV画布中的图片节点,串联起后续的视频生成,这意味着它不是孤立的工具,而是嵌入在整个创作生态中的一个锚点,提升的是整条创作管线的可控性。
此前短剧自习室报道过,LibTV3月份上线首日就迎来10万用户访问,平均每个月推出18个新功能,超过300家短剧公司及影视工作室成为其B端客户,多位创作者制作出了爆款作品。
比如2026年北京国际电影节AIGC短片组最佳影片《牡丹记》,由3个人花了2000块、2个月时间,使用LibTV制作。

(相关动图)
抖音博主@菲菲飞 则做出了全网百万点赞的现实题材AI短片《阿黄》,原本需要大量人力物力才能实现的想法,最后由三个人用一周左右时间、约7000元的算力成本就完成了。

(相关动图)
LibTV的功能更新历史——从让创作者能够生成,到能够一站式生成、团队协作生成、3D构图参考生成,一定程度上映射出AI工具竞争维度和行业锚点的变化。
放在更宏观的行业视角来看,当Seedance 2.0等模型已经将画质推至电影级,行业焦点逐渐从生成效果转向生成控制和生产成本。LibTV导演台所代表的“构图可视化+低成本生成”方向,踩中的正是AI视频商业化的降本增效节点。
说到底,AIGC创作者的需求从来都很朴素,他们想要的是一个能把脑子里的画面准确复现出来的工具,好沟通,不费钱。而随着这些专业工具链的持续迭代,创作走到台前,这条路正在变得越来越清晰。
*【近期福利】创作会员低至3.7折,最多送160条Seedance 2.0,团队版最多送2000条,Seedance 2.0 VIP不排队,低至0.36元/秒。
PS:欢迎扫描下方海报二维码,预约《2026上半年AI短剧行业报告》。

| 往期好文推荐
12个平台激战漫剧赛道:分成高达90%,AI内容进入亿级流量
两个月上线三部AI精品漫剧,单剧4天播放破千万,行业进入分水岭?
中文在线首部AI 3D漫剧播放量破5000万,这个新的细分赛道要火了?
上市公司财报里的AI短剧真相:3个月烧掉4亿,由译制剧向本土剧迁移......